
-
Ajouter aux favoris


Prenez-les, nous ne sommes pas avares !
lundi 19 décembre 2016
Fuites, fuites, fuites ... Comment nos données tombent-elles dans les mains des malfaiteurs ? Une partie des fuites se produisent à cause du piratage, car les réseaux d'entreprise contiennent des vulnérabilités et des erreurs de configuration. Mais il y a des fuites particulières, absurdes, qui peuvent difficilement être appelées des fuites, puisque dans ce cas, les propriétaires mettent eux-mêmes des données en accès libre : difficile de ne pas en profiter. Comment ça marche ?
Tout le monde connaît le principe de la recherche sur le web. Les robots de recherche examinent les ressources disponibles sur le Web et leur attribuent des index en utilisant des algorithmes spécialisés, puis à la demande de l'utilisateur, ils affichent des résultats. Mais toutes les ressources ne sont pas indexées. De plus, une ressource peut demander à un robot de recherche de mettre un document à la disposition de tout le monde. Le problème est que les robots de recherche, lorsqu'ils détectent un site, ne commencent pas l'indexation immédiatement. D'abord, ils recherchent le fichier robots.txt, un fichier texte se trouvant dans le répertoire racine du site et qui contient des instructions de recherche. Ces instructions peuvent interdire l'indexation de certaines sections ou pages du site, pointer sur le bon "miroir" du domaine, recommander au robot de respecter un délai entre les téléchargements de documents sur le serveur etc.
Par exemple, une entrée dans le fichier Disallow: /about interdit l'accès à la section http: // __ nom du site __ / about / et au fichier http: // nom du site / about.php.
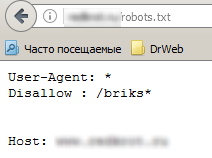
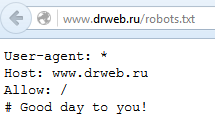
Mais sachant que le fichier robots doit être situé dans le répertoire racine du site, il peut être ouvert directement en spécifiant le chemin dans le navigateur. Si on ouvre le fichier, on peut voir les chaînes auxquelles l'accès est fermé pour les moteurs de recherche.
Essayons d'y entrer et voyons :
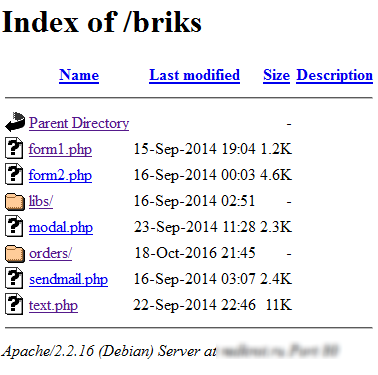
Qu'est ce qui se trouve dans le dossier orders ? Effectivement, ce sont des documents secrets !

A part cela, les liens vers des endroits " secrets " peuvent se trouver dans le code de la page d'accueil :

Que se passe-t-il si les développeurs du site n’ont pas fait attention ? Supposons que vous avez créé votre propre site web ou que vous aidez un de vos amis à en construire un. Aujourd'hui, il est assez facile de créer un site web. Faute d'expérience en recherche de vulnérabilités, vous préférerez vous fier aux professionnels, et c'est une bonne décision. Et tout à coup, vous trouvez un site vous proposant de vérifier si votre site est bien protégé contre le piratage, et le service que l’on vous propose est beaucoup moins cher qu’ailleurs.
Nous n'allons pas citer l'adresse du site en question, mais l'histoire est fraîche et très révélatrice.
Ainsi, le pirate qui obtient l'accès au site nouvellement créé obtient du même coup le nom de l'administrateur système, son numéro de téléphone etc.
Et sans aller aussi loin, une simple recherche peut permettre de trouver des documents secrets appartenant à des organisations très solides.
Une publication de documents depuis différents sites d'organismes russes marqués " Pour usage officiel " a eu lieu dans les résultats des moteurs de recherche le 27 juillet 2011. Des documents marqués " Pour usage officiel " appartenant au FAS (Federal Antimonopoly Service of Russia), au Service fédéral des migrations (SFM de Russie), à la Chambre des Comptes, au Ministère du Développement économique, ainsi qu' à la Direction principale des programmes spécialisés du président de la Russie et beaucoup d'autres ont été disponibles dans tous les principaux moteurs de recherche: " Yandex ", Google, Mail.ru et Bing.
Auparavant, plus de 8.000 messages SMS envoyés depuis le site de l'opérateur mobile " Megafon " se sont trouvés en réseau en accès libre, de même les statuts des commandes sur les boutiques en ligne, y compris les sex shops, et une autre fuite de données concernant les passagers depuis les sites Tutu.ru et Railwayticket.ru. Les données personnelles des clients des magasins se sont trouvées en accès public : leurs noms, les noms des produits commandés, les adresses de livraison, les adresses e-mail et des données des passagers ainsi que des informations sur les tickets de train et les numéros des passeports.
http://ekb-security.ru/news/2970-lr-lr-google.html
Le projet Lumières sur la sécurité recommande
Faites confiance, mais vérifiez. Et un message spécial aux amateurs de secrets : nous n'avons pas de secrets pour vous !
![[Twitter]](http://st.drweb.com/static/new-www/social/no_radius/twitter.png "Partagés 15 fois")
Nous apprécions vos commentaires
Pour laisser un commentaire, vous devez accéder au site via votre compte sur le site de Doctor Web. Si vous n'avez pas de compte, vous pouvez le créer.
Commentaires des utilisateurs
Bernard
11:20:28 2016-12-19